
In this blog, we will help you learn about building a web scraper that will help you scrape data on prices and delivery status of liquor from More, Total Wine, and other stores.
The main idea of this blog is to tell you How to Scrape Liquor Pricing and Delivery Status Data from Total Wine Stores and how Actowiz Solutions can help you in that.
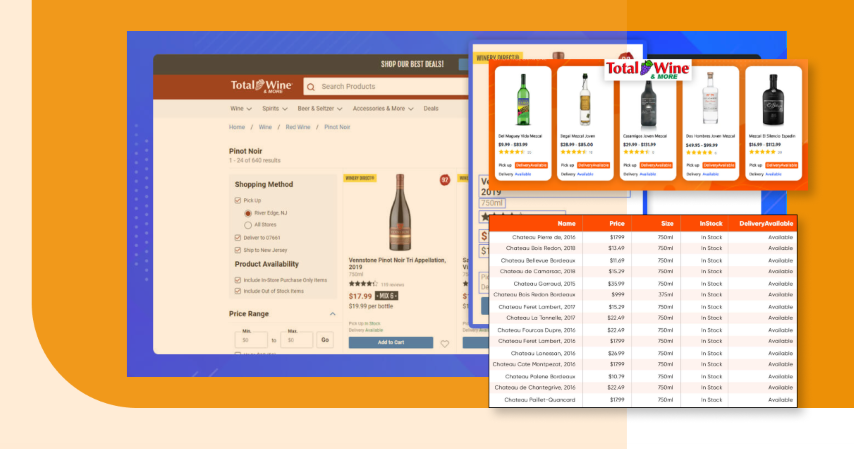
To help you with data extraction of liquor delivery status and prices from different stores, we will utilize Python 3 along with Python libraries. Let us know about the data fields fetched into an excel sheet:
- Name
- Size/Quantity
- Price
- URL
- Delivery Available
- InStock
You will get the data extracted in CSV file format which would like the data shown in the image below:

Required Package to Install For Running Total Wine and More Web Scrapers
We will start with the installation of Python 3 for data extraction along with the Python libraries given below
Python requests – Use to create requests & download HTML scripts of webpages.
Selectorlib – Used for data extraction with the help of YAML files created from the downloaded web pages.
Now, you need to install them using pip3 using the command given below
pip3 install requests selectorlib
The Python Code
Now, simply create a file with the name products.py and then paste the following code into it.
Research on Customer Statistics and Preferences
To live in the competitive e-commerce industry, you have to identify the requirements and wishes of your targeted market. Utilize e-commerce data scrapers to scrape as well as analyze the array of services and products your competitors offer to find a superior idea about how to grow your business.
As a lot of new services and products come into the market daily, utilize e-commerce product scrapers and data scrapers to make a listing of all services and products that competitors provide. After that, you can utilize keywords for going through the listing and understand which services and products you can provide to get an edge over your e-commerce stores.
You may also utilize data scraping for doing predictive sentiment analysis for determining what your clients are discussing about. By extracting through different social media websites, it’s easy to collect important statistics regarding consumers’ experiences, preferences, as well as opinions on different services and products. It will assist you in boosting your business’s user experience and appeal.
Now, let’s look at the result of executing the above code:
It reads through a list of Total Wine stores from url.text file. (The url.text file comprises URLs for product pages for different beverages like Wines, Scotch, Beer, etc)
It utilizes selectorlib YAML file that finds the data on a particular page of Total Wine. It is then saved as a file named selectors.yml.
The code performs data scraping to yield the desired information.
It saves the data in CSV format as data.csv
Construct YAML File – selectors.yml
Now, you will see that there is a file used in the above code known as selectors.yml. The file helps simplifies the code and keeps it transparent. It is a Web Scraper tool named as Selectorlib that helps create the file selectors.yml.
Knowing More About the Efficient Tool – Selectorlib
It is an efficient tool that enables effortless marking up, selection, and web data extraction through web page visuals.
The Selectorlib Web Scraper Chrome Extension allows you to mark the desired data and prepares the CSS Selectors/XPaths required for data extraction. Also, it helps you preview how the data appears to be.
Note that if you want only the data just like the data shown above, then you do need to rely on Selectorlib.
Now, you can see the fields being marked up for data to enable data scraping with the help of Selectorlib Chrome Extension.
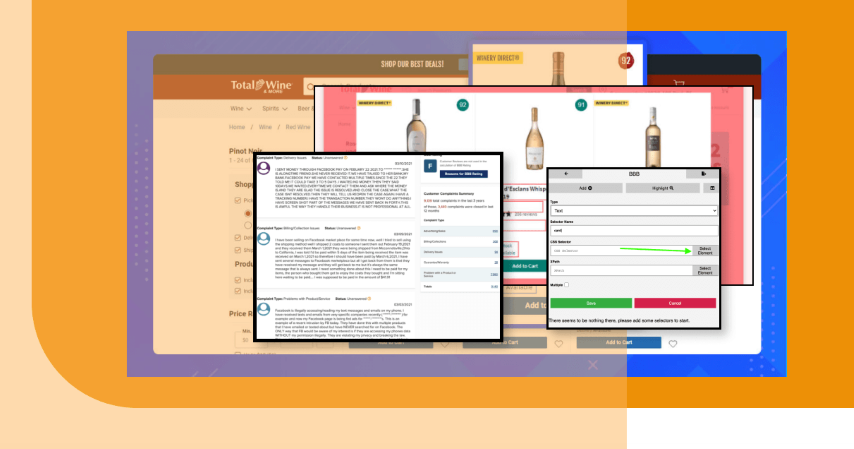
After you have finished building the template, just click on “Highlight” to show up preview the selectors. Lastly, click on “Export” and then download the file – YAML which is the selectors.yml file.
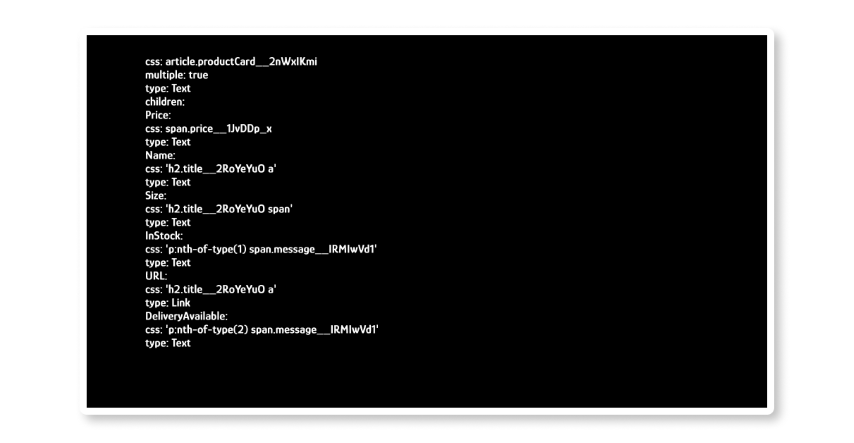
This is how your template file (selectors.yml) would appear like
Run Total Wine & More Scraper
Here, you need to include the URL that you wish to scrape into urls.txt (text file) in a similar folder.
Here is the content of the urls.txt file
https://www.totalwine.com/spirits/scotch/single-malt/c/000887?viewall=true&pageSize=120&aty=0,0,0,0
Now, use the following command to run the scraper
python3 products.py
Challenges You May Face Using the Code and Other Tools or Copied Scripts Taken From the Internet
Code degenerates with time and as the website changes. Thus, code or old scripts corrupt with time.
Some of the problems you may come across using this code/tool not maintained for long are
With the change in website structure, for instance, the CSS selector used above to determine Price in the file selectors.yml (price__1JvDDp_x) is prone to change with each passing day.
The website can obstruct IP address/Ips from the Proxy provider
The website can obstruct the design for restoring the script’s uses
The website can also restrict a user-agent
The website can include fresh data points or change a new one
Conclusion
To overcome the above challenges and many others, you can seek consultation from expert web data extraction companies like Actowiz Solutions for better data insights. We help you eliminate the hurdles faced after using internet-based DIY scripts and tools. We assist you to avoid trial and error and offer web scraping services that prevent the degeneration of code in the long run. With the help of our skilled API developers,’ you can sail through an easy scraping process even for complex projects. Let us connect to discuss your data scraping needs today.